
前言
最近,deepseek r1的大模型比较火,然后,官方的经常会无法响应,可能是用的人太多了。但是,它胜在开源,并且发布了基于r1模型蒸馏后的小模型。于是,本地部署deepseek的方案就诞生了。经过我的一番折腾,我的本地部署大模型的解决方案就决定是ollama+page assist.
ollama是一个便捷的大模型管理器,page assist是chrome插件。
安装ollama
下载ollama的安装包,先别急着安装。因为它默认是安装在c盘的,怕你c盘不够用。我是装在E盘,考虑到不是都会分出有E盘,这里以装在D盘为例。
例如我现在想把ollama安装在D:\Ollama路径下,以Windows系统为例
- 1、把下载好的安装包(也就是OllamaSetup.exe)放到D:\Ollama路径下
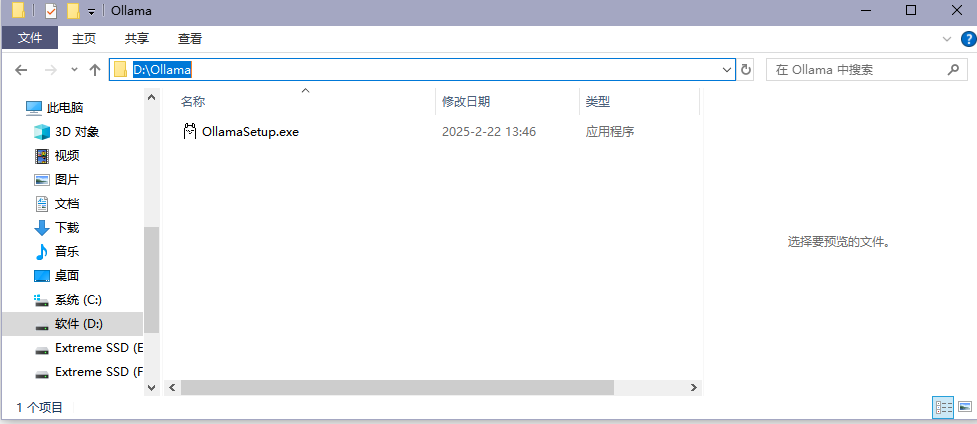
- 2、打开下载安装包的文件夹,在地址栏(上图蓝色那块就是)输入cmd打开
- 3、输入
OllamaSetup.exe /DIR=D:\Ollama就能跳转到ollama的安装界面
然后傻瓜式一路下一步就能安装完成了。因为我已经安装了,就不再进行安装演示。
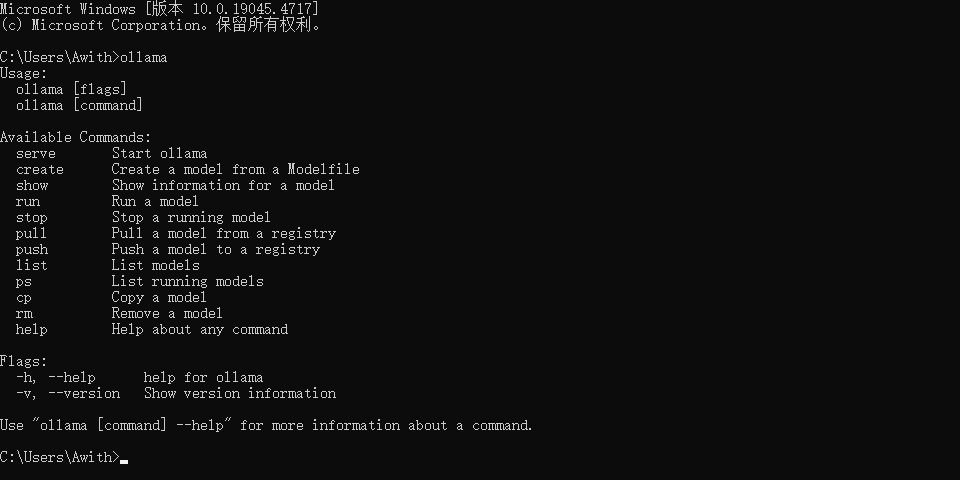
cmd窗口输入ollama,出现如下图的信息,即为安装成功。
下载deekspeek模型
还是ollama官网,点击deepseek r1,然后可以选择对应的模型

先别急着下载,模型很可能直接下到C盘的。
想将模型下载到 D 盘,可以通过以下方法实现:
通过设置环境变量 OLLAMA_MODELS,可以指定 Ollama 存储模型的路径。
- 打开环境变量设置:
- 右键点击“此电脑”或“我的电脑”,选择“属性”。
- 点击“高级系统设置”。
- 在“系统属性”窗口中,点击“环境变量”。
- 新建系统变量:
- 在“系统变量”部分,点击“新建”。
- 输入以下内容:
变量名:OLLAMA_MODELS
变量值:D:\ollama_models(或你希望存储模型的路径)
然后在进行模型的选择。模型的选择根据你电脑的显存和内存进行。尽量将模型完全放在显存去跑。例如我的是16G显存的4060ti和32G内存,所以可以选择32b的模型运行,但是因为不是完全在显存跑,所以回复的速度会很慢。所以我又选择了14b的模型进行下载。这里推荐再下载一个1.5b的模型,模型小,虽然回复的质量不行,但是需要的硬件资源小,在进行本地ai相关应用开发的时候使用还是很不错的。
选好后复制旁边的命令,在cmd,就会进行模型的下载,并且启动。
出现以下界面的时候,就代表模型安装好了。
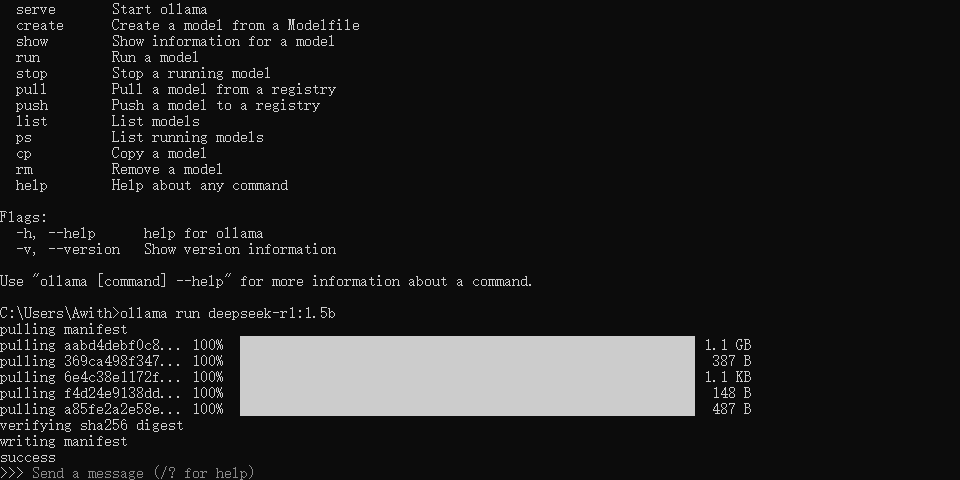
就可以与本地的ai进行chat
安装Page Assist
打开谷歌浏览器,然后去插件商店下载扩展即可。
打开插件的页面,就摆脱了终端窗口,有了ui界面。
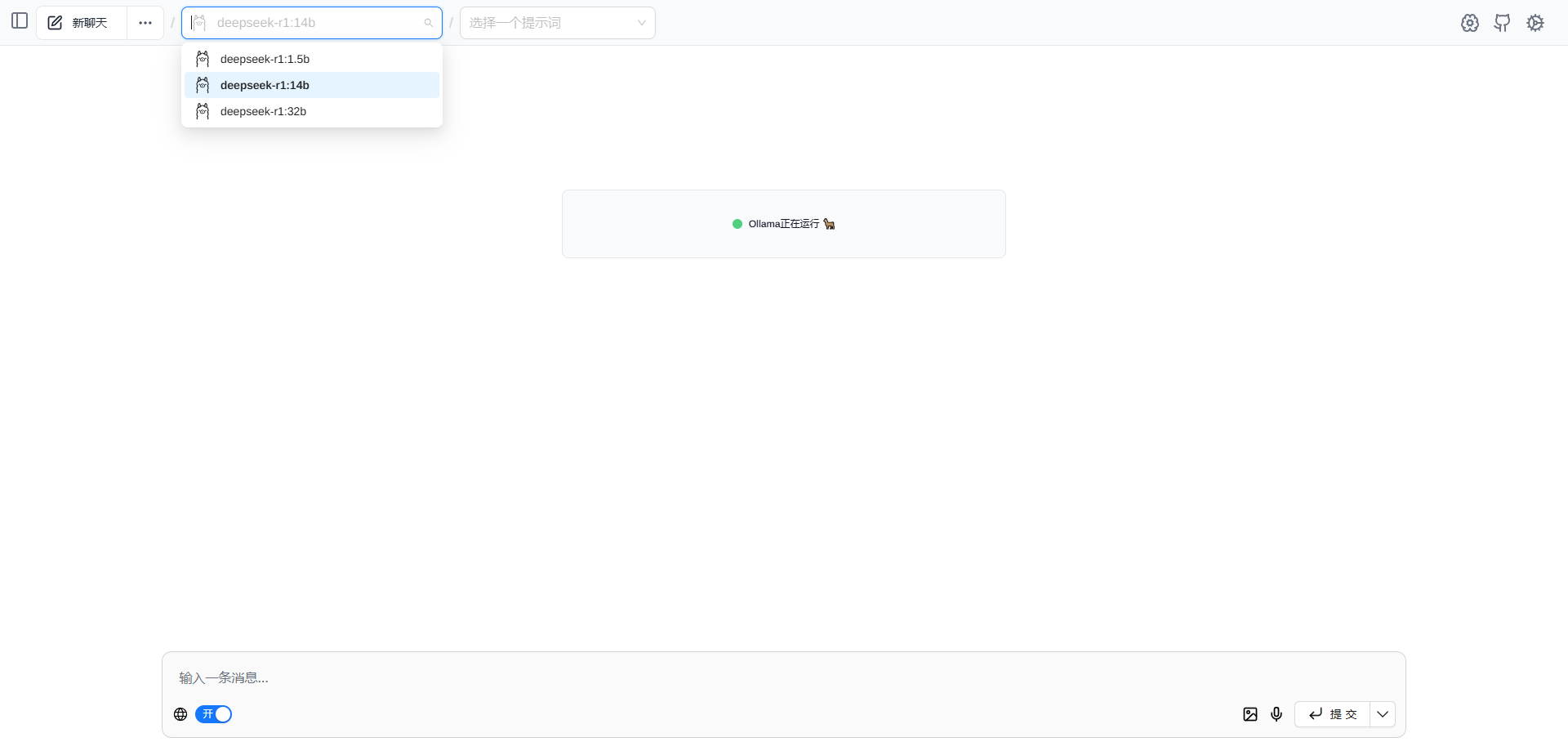
选择模型,然后进行问答。
至此,你已经拥有了一个本地部署的大模型。
其他
以下是ollama官方仓库对api调用模型的介绍。
REST API
Ollama has a REST API for running and managing models.
Generate a response
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt":"Why is the sky blue?"
}'
Chat with a model
curl http://localhost:11434/api/chat -d '{
"model": "llama3.2",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
See the API documentation for all endpoints.
如果想在自己程序中调用本地的大模型生成答案,可参考我用ai使用python写的一个代码。
import requests
import json
from config import Config
from logger import get_logger
class ModelClient:
def __init__(self, endpoint: str = Config.OLLAMA_ENDPOINT, model: str = Config.LLM_MODEL):
"""
初始化 ModelClient。
:param endpoint: Ollama 服务的地址。
:param model: 使用的模型名称。
"""
self.endpoint = endpoint
self.model = model
self.logger = get_logger("ModelClient") # 获取日志记录器
self.logger.info(f"模型客户端初始化完成。Endpoint: {self.endpoint}, Model: {self.model}")
def generate_answer(self, prompt: str) -> str:
"""
使用 Ollama 模型生成回答。
:param prompt: 用户输入的问题。
:return: 模型的完整回答。
"""
self.logger.info(f"请求模型回答,问题: {prompt}")
try:
response = requests.post(
self.endpoint,
json={"model": self.model, "prompt": prompt},
stream=True # 使用流式响应
)
response.raise_for_status() # 检查请求是否成功
# 初始化完整回答
full_answer = ""
# 遍历流式响应
for line in response.iter_lines():
if line:
decoded_line = line.decode("utf-8")
# self.logger.debug(f"接收到响应行: {decoded_line}")
try:
data = json.loads(decoded_line)
if "response" in data:
# 拼接 response 内容
full_answer += data["response"]
print(data["response"], end="", flush=True) # 实时输出
if data.get("done", False): # 检查是否完成
self.logger.info("模型返回完成标志,结束拼接。")
break
except json.JSONDecodeError:
self.logger.error(f"解析响应行时出错: {decoded_line}")
continue
return full_answer # 返回完整回答
except requests.exceptions.RequestException as e:
self.logger.error(f"请求模型时发生错误:{e}")
return f"请求模型时发生错误:{e}"
其中,配置中的内容为,
OLLAMA_ENDPOINT = "http://127.0.0.1:11434/api/generate"
LLM_MODEL = "deepseek-r1:14b"
其他我暂时也还没有探索。
也可参考使用C#,导入对应的包直接开箱即用
using Microsoft.Extensions.AI;
using OllamaSharp;
using System.Net.Mail;
namespace OllamaApiTest
{
class Program
{
static async Task Main(string[] args)
{
Uri modelEndpoint = new("http://localhost:11434");
//指定模型
string modelName = "deepseek-r1:14b";
var chatClient = new OllamaApiClient(modelEndpoint, modelName);
while (true)
{
Console.Write(">>> 请输入您的问题:");
//提问
string? question = Console.ReadLine();
if (question == "exit") break;
if (!string.IsNullOrEmpty(question))
{
var response = chatClient.GetStreamingResponseAsync(question);
Console.WriteLine($">>> 你: {question}");
Console.Write(">>> ");
Console.WriteLine(">>> DeepSeek: ");
//输出
await foreach (var item in response)
{
Console.Write(item);
}
Console.WriteLine();
}
}
}
}
}